
Owners of websites can teach web crawlers and other web robots on how to access the pages on their website by including instructions in the robots txt file. It can be applied in a variety of circumstances, such as prohibiting bots from accessing private data or instructing search engines on what content to index. In this article, we’ll define robots.txt and discuss how your website can benefit from having one.
Although it’s not a meta tag, sitemap, XML file, or anything else similar, robots.txt is a file you write to tell web crawlers how to crawl the pages on your website.
You can instruct the robots how to browse your website in the robots.txt HTTP request header. What’s best? What goes in this file is entirely up to you; there are no strict guidelines! If there are no concerns with how they are accessed through HTTP requests and headers like User-Agent strings, you may decide not to build one at all. This applies if you don’t want some pages of your site to be crawled (like private material).
Robots.txt is a file that you can use to block search engines from crawling your site.
Robots.txt is also used by bots, or spiders and crawlers, to prevent them from indexing pages on your website.
There are many different types of bots that you might encounter when using robots.txt: Googlebot, Bingbot, YandexBot… and many others!
A robots.txt file is normally used to prevent search engines from crawling and indexing your website. This is usually done for websites that are under construction, or for sites that you don’t want search engines to find at all.
You can use a number of tools to check your existing robots.txt file. One of them is the Google product called Robots Exterminator. In order to make things simpler for you when debugging, you can also use the search box at the top of this page to hunt up the information you need in your existing robots.txt file and save it as a PDF or MS Word document with a copy of this website’s text.
Let us know if you’re using another tool, thanks!
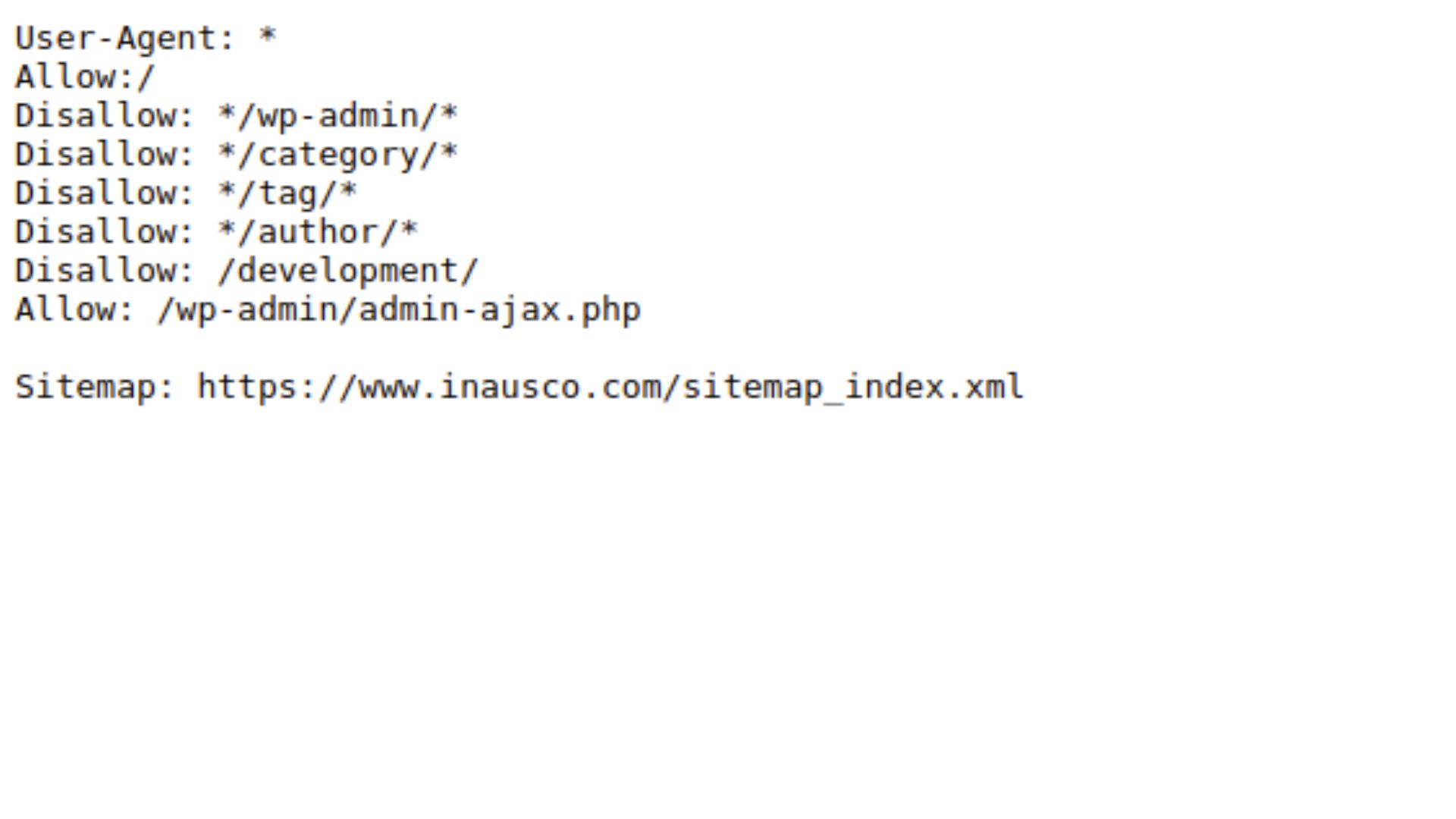
A robots.txt file has the following simple syntax:
The file must start with the string “/robots” and be in plain text format.
“User-agent” or “Disallow” will be the next section, if there is one.
Keep in mind that if you want to restrict access to your site for a number of agents or particular kinds of requests, you can have numerous deny directives. Each directive in this situation should adhere to the preceding format: The command “/dis” is followed by one or more lines that list the agents or categories of requests that should be disallowed by that directive.
/robots/noindex/user agent@example.com; /robots/noindex/.*.php$; and /robots/noindex/all are a few examples.
A text string known as the user-agent serves to identify the web browser. Although its primary use is to determine the type of browser being used, it can also be used for other things, like spotting bots on your website.
When deciding whether or not to follow redirection from one URL to another, browsers use this information (if there are any). For instance, if you want all of your images to be housed on Google Drive and reachable via https://www2.googleapis.com/drive/v1/images?id=…, you should ensure that the following sentence appears in your robots.txt file:
Googlebot as the user agent
Refuse: */images
Disallow is a directive that tells search engines not to crawl the specified URL.
While this might sound like common sense, it can be useful for websites with sensitive content or functionality and want to prevent indexing of those pages by search engines (and other web crawlers). For example, if you have an online store selling illegal items and you don’t want Googlebot seeing your site’s homepage linking directly to them, then use
Disallow: /products/drugs-for-sale
The user agents that are permitted to crawl the specified URL are listed in the allow directive.
Either an absolute or relative path to the root directory is possible. Wildcards are permitted, but / or * are not permitted. Instead of specifying it above, use its own file name if you only want a particular subdirectory.
The search engine is instructed on how long to wait between visits to a specific page using the Crawl-Delay directive. This can be helpful if you don’t want to overwhelm the website with requests or if it’s an older website that hasn’t seen much activity recently.
For instance:
Google will view every other page after 3 minutes, but not before, if your website only has 10 pages and each of them has a Crawl-Delay value of 300 seconds (3 minutes). It functions similarly to an additional button that may be hit at any moment and will remain pressed until a user clicks somewhere else on your website or closes their browser window completely.
A sitemap is a list of every page on your website, categorised. These lists are used by search engines to choose which websites should appear higher in search results.
Because it lets them know where you’re hiding crucial information on your website, a sitemap aids in increasing Google traffic to your website:
The content pages, or what can be seen when a user lands on one
Internal connections between those pages (i.e., how they connect together)
To be more precise, let’s look at the bullets. Robots.txt files are a really great tool for your website.
Now that you understand how robots.txt files work, here are some more articles you can read to learn more about SEO and digital marketing concepts:

